5.1 KiB
uploader进程优化
描述
数据上报(upload)进程,基本流程是订阅kafka消息,然后按项目进行编码上报。目前处理的流程如下图:
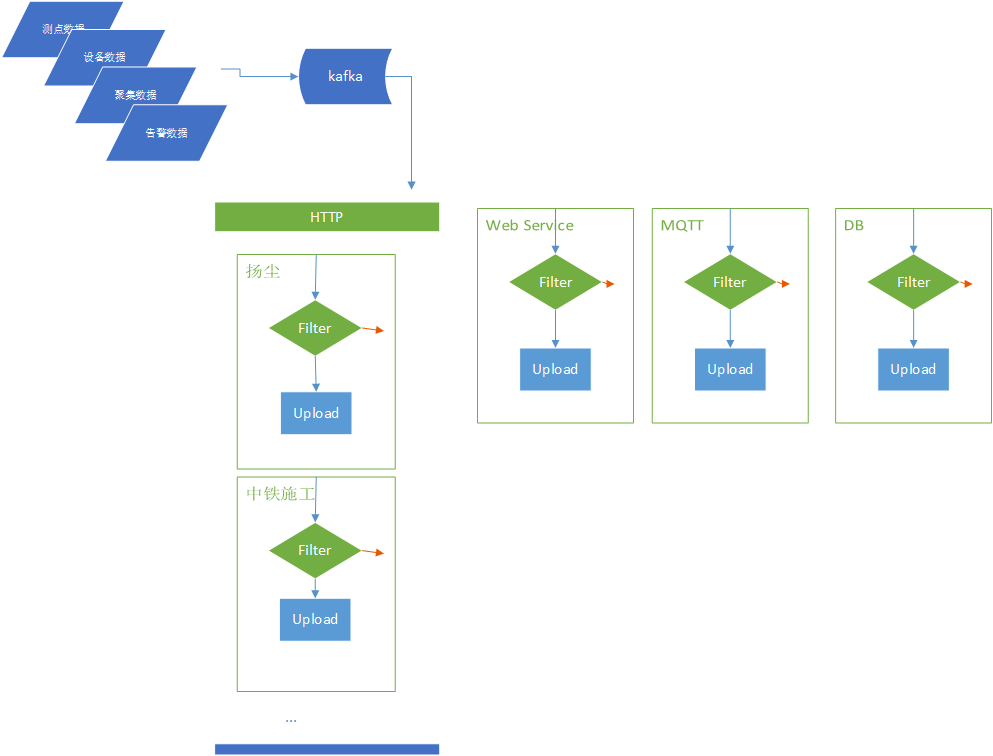
所有项目上报代码通过继承uploader接口实现consumer。数据消息通过scala的par方法并发执行。但是一次消息流的处理,取决于最后一个任务的处理完成时间。这就会造成最终整体处理的积压。这是目前uploader进程性能的主要缺陷。
同时,在例如http_comm这类通用uploader中,会处理多个项目的上报,其中多个项目之间是同步依次执行的。这也是
随着上报项目的增多,该流程模式可能会出现性能上的问题(实际上,知物云上报中已出现类似问题,解决方法是通过将不同的uploader拆解出来,作为不同的进程执行)。
可行方法
Node-Red事件驱动引擎
它是可通过界面配置实现数据流转的第三方规则引擎。参见《规则引擎》。
缺点:自带的一些组件(Node)只能实现较为简单的函数转换和网络推送,在已知项目处理经验来看,它不能满足大部分的推送场景。
建议:作为平台扩展功能。不在此次优化范围内
Actor模式
一种基于消息模式的多线程处理,每个Actor原子实体都有自己的存储状态(State)、行为(behavior)、邮箱(MailBox)。actors之间是相互隔离的,外部无法访问Actor的状态(不存在数据共享的问题); 每个actor会同步处理接收的消息,接收的消息会放入mailbox(消息队列);
在此种设计模式中,我们将我们的uploader(上报的工作者)作为独立的actor。这样不同的actor之间是解耦的,而actor内部处理消息又是顺序的。

java库 Akka-Actor:
http://edisonxu.com/2018/10/30/akka-actor.html
将每个上报工作者(uploader)转换为actor,并处理kafka消息数据。
def initActors(): Unit = {
actors =
uploaders.map(u => akkaSystem.actorOf(Props(classOf[UploadActor], u)))
}
def handleActor(data: Any): Unit = {
actors.foreach(actor => actor ! data)
}
缺陷:所有uploader任务运行在同一进程,还是可能出现故障导致整体崩溃问题; 不支持水平横向扩展;Actor中mailbox不可能无限接收缓存,可能出现OOM;
建议:使用此方法进行第一步优化,可部分解耦upload任务关联
Flink
思路:使用Flink的KeyBy函数,实现不同推送的子任务执行。
Flink中的keyBy不会改变数据的每个元素的数据结构,仅仅时根据指定的key对输入数据重新划分子任务,相同的key对应的元素会被划分到一个子任务当中。
// alarm-stream operators
env.addSource(kafkaConsumer)
.map {
parse _
}
.flatMap(new UploadFlatMap) // filter & construct upload task
.keyBy(_._1) // key by upload worker
.addSink(new UploadSink) // do upload sink
// execute program
env.execute("Upload flink")
// 创建上报任务
class UploadFlatMap extends RichFlatMapFunction[IotaData, (uploader, IotaData)] {
override def flatMap(value: IotaData, out: Collector[(uploader, IotaData)]): Unit = {
UploadConsumer.uploaders.filter(
// 判断数据是否被当前uploader包含
uploader => uploader.filter(value)
).foreach(
// 构造upload任务(创建数据副本)
uploader => out.collect((uploader, value))
)
}
}
// 执行上报任务
class UploadSink extends RichSinkFunction[(uploader, IotaData)] {
override def invoke(value: (uploader, IotaData)): Unit = {
val uploader = value._1
val data = value._2
uploader.upload(Array(data))
}
}
这样不同upload任务可以通过flink 的分布式散列到不同的任务中执行。需要测试keyby后不同任务是否会相互干扰
以上仅处理了IotaData,其他数据的上报一样处理
分进程
这是目前知物云性能瓶颈后使用的优化方法;已通过配置和反射实现启动不同的upload任务
lazy val consumers: String = props.getProperty("consumers", "*")
if (consumers == "*") {
// 处理所有的upload任务
Array[uploader](http_comm, qingdao_kancha, huhanggaotie, http_mawan)
} else {
consumers.split(",").map(c => fromName(c))
}
/**
* 通过反射获取上传类
*
* @param name 类名称
* @return
*/
def fromName(name: String): uploader = {
val cn = classOf[uploader].getPackage.getName + "." + name
val runtimeMirror = universe.runtimeMirror(getClass.getClassLoader)
val module = runtimeMirror.staticModule(cn)
runtimeMirror.reflectModule(module).instance.asInstanceOf[uploader]
}
缺陷:增加了运维的复杂度;没有复用kafka消费者,可能导致kafka性能的浪费;
建议:通过前面提的几种方式,做进一步优化。